|
I am a postdoctoral researcher in the Department of Computer Science and Technology, Tsinghua Univerisity, collaborated with Prof. Jie Tang. Prior to that, I received my Ph.D. from the Knowledge Engineering Group (KEG), Department of Computer Science and Technology of Tsinghua University, fortunately working with Prof. Jie Tang. I obtained my master and bachelor degree from Tsinghua University and Xidian University, respectively. My current research interests lie in multimodal coding agent, specialized mathematical models, large language models, multi-modal large language models, and graph representation learning. If these areas align with your interests, I welcome you to reach out via email. I am always open to discussing potential collaborations and exploring new ideas together. Email: yang-zhen [at] mail.tsinghua.edu.cn / Google Scholar / Github |

|
|
|
|
|
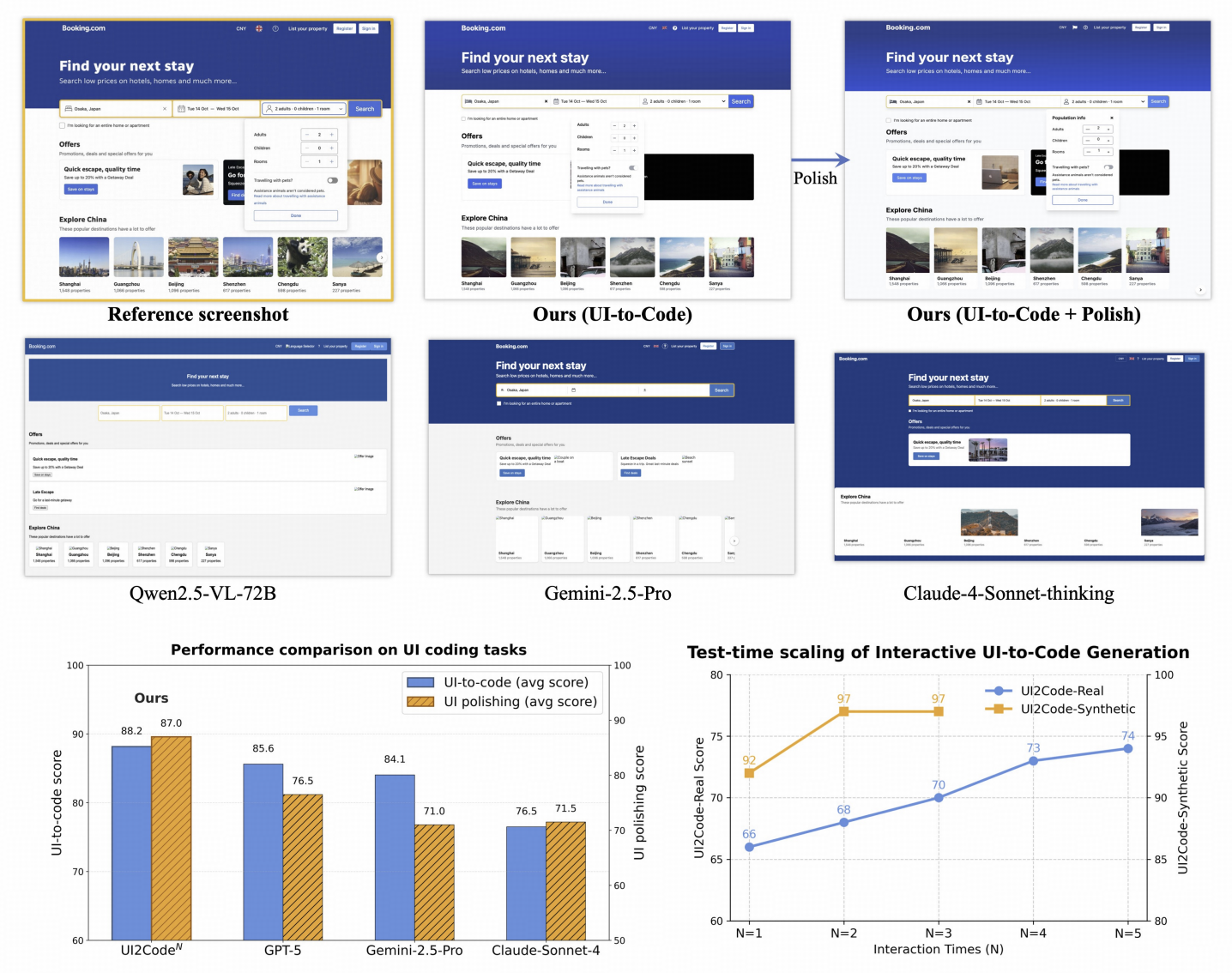
Zhen Yang*, Wenyi Hong*, Mingde Xu, Xinyue Fan, Weihan Wang, Jiele Cheng, Xiaotao Gu, Jie Tang arXiv, 2025 paper, code UI2Code^N is a visual language foundation model trained through staged pretraining, fine-tuning, and reinforcement learning to achieve foundational improvements in multimodal coding, which unifies three key capabilities: UI-to-code generation , UI editing , and UI polishing. (1) Interactive UI-to-Code Paradigm – We redefine UI-to-code generation as iterative reasoning with visual feedback, enabling flexible code generation, editing, and test-time scaling (e.g., +12% improvement with four rounds of polishing). (2) First open-source Unified UI2Code Model – UI2CodeN is the first open-source VLM to jointly support UI-to-code, UI editing, and UI polishing, achieving state-of-the-art results on Design2Code, Flame-React-Eval, and Web2Code, outperforming Gemini-2.5-Pro and Claude-4-Sonnet. (3) Full Training Recipe for Coding VLM – We are the first to release a complete three-stage training pipeline—pretraining, supervised fine-tuning, and reinforcement learning with a novel reward design—balancing data realism with code generation quality. |
|
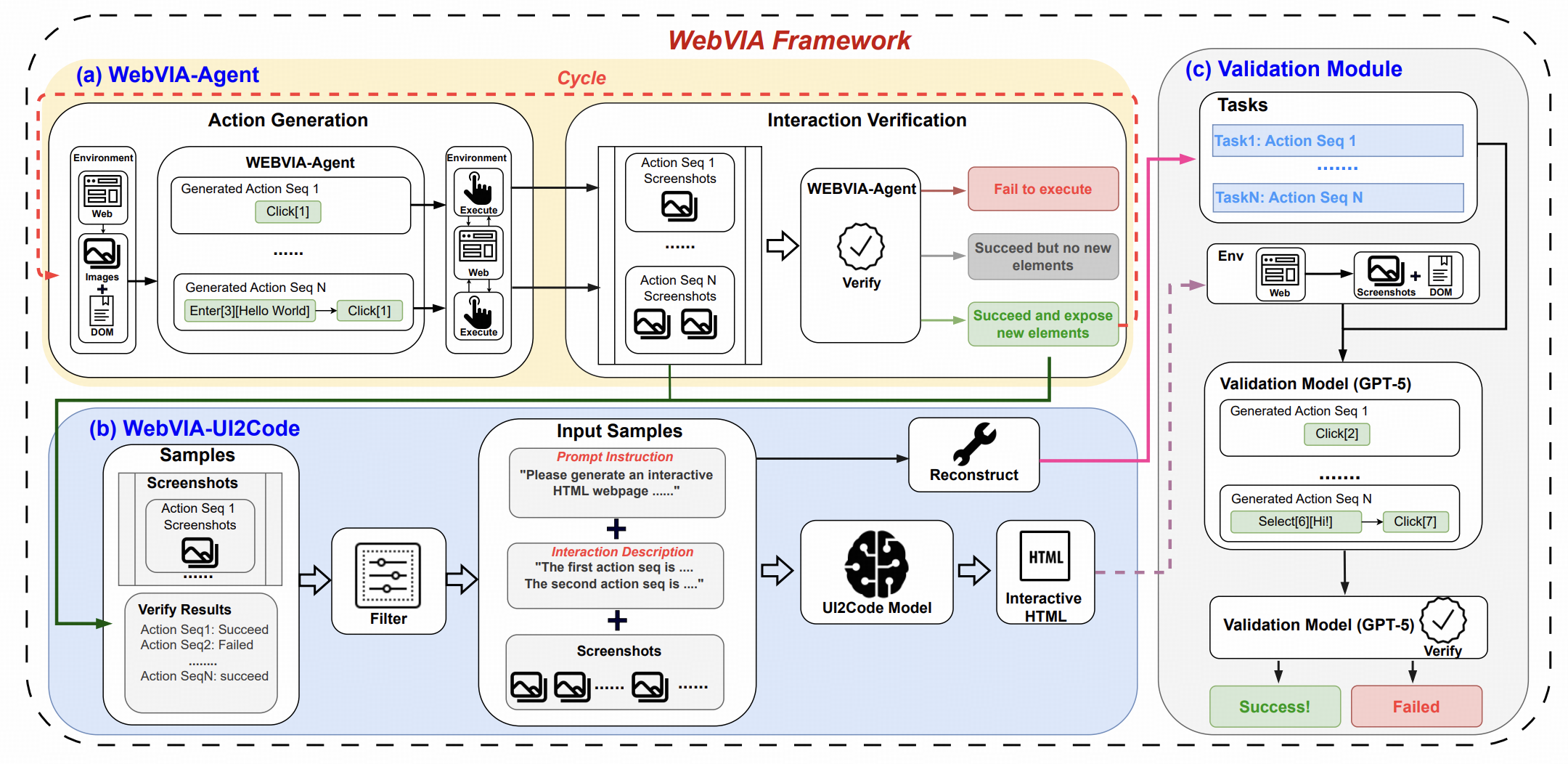
Mingde Xu*, Zhen Yang*, Wenyi Hong, Lihang Pan, Xinyue Fan, Xiaotao Gu, Bin Xu, Jie Tang arXiv, 2025 paper, code WebVIA is the first agentic framework for interactive and verifiable UI-to-Code generation. While prior vision-language models only produce static HTML/CSS layouts, WebVIA enables executable and interactive web interfaces. The framework consists of three modules: (1) WebVIA-Agent – navigates websites and captures multi-state UI screenshots. (2) WebVIA-UI2Code – generates functional HTML/CSS/JavaScript code with interactivity. (3) Validation Module – verifies whether the generated UI behaves as expected. WebVIA-Agent achieves more stable and accurate UI exploration than general-purpose agents (e.g., Gemini-2.5-Pro), and WebVIA-UI2Code significantly improves executable and interactive code generation across multiple benchmarks. |
|
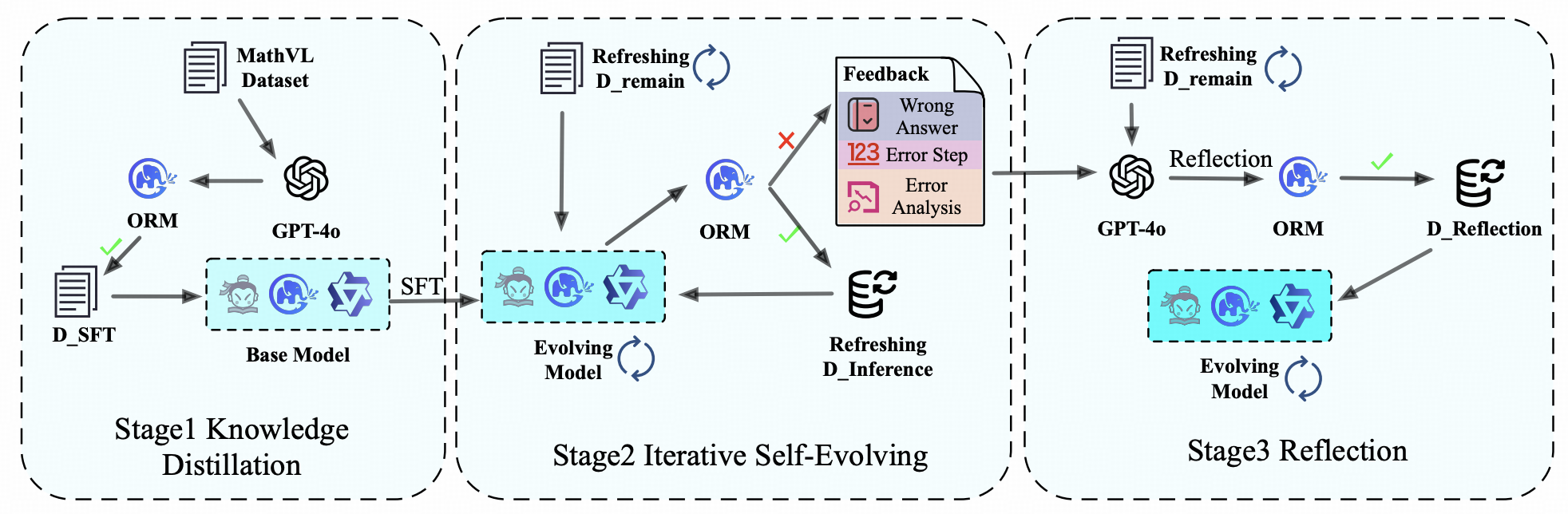
Jinhao Chen*, Zhen Yang*, Jianxin Shi, Tianyu Wo, Jie Tang AAAI 2026 paper, code MathSE unifies distilled supervision, an Outcome Reward Model (ORM), and reflection-driven data refresh to progressively enhance math reasoning in multimodal LLMs. |
|
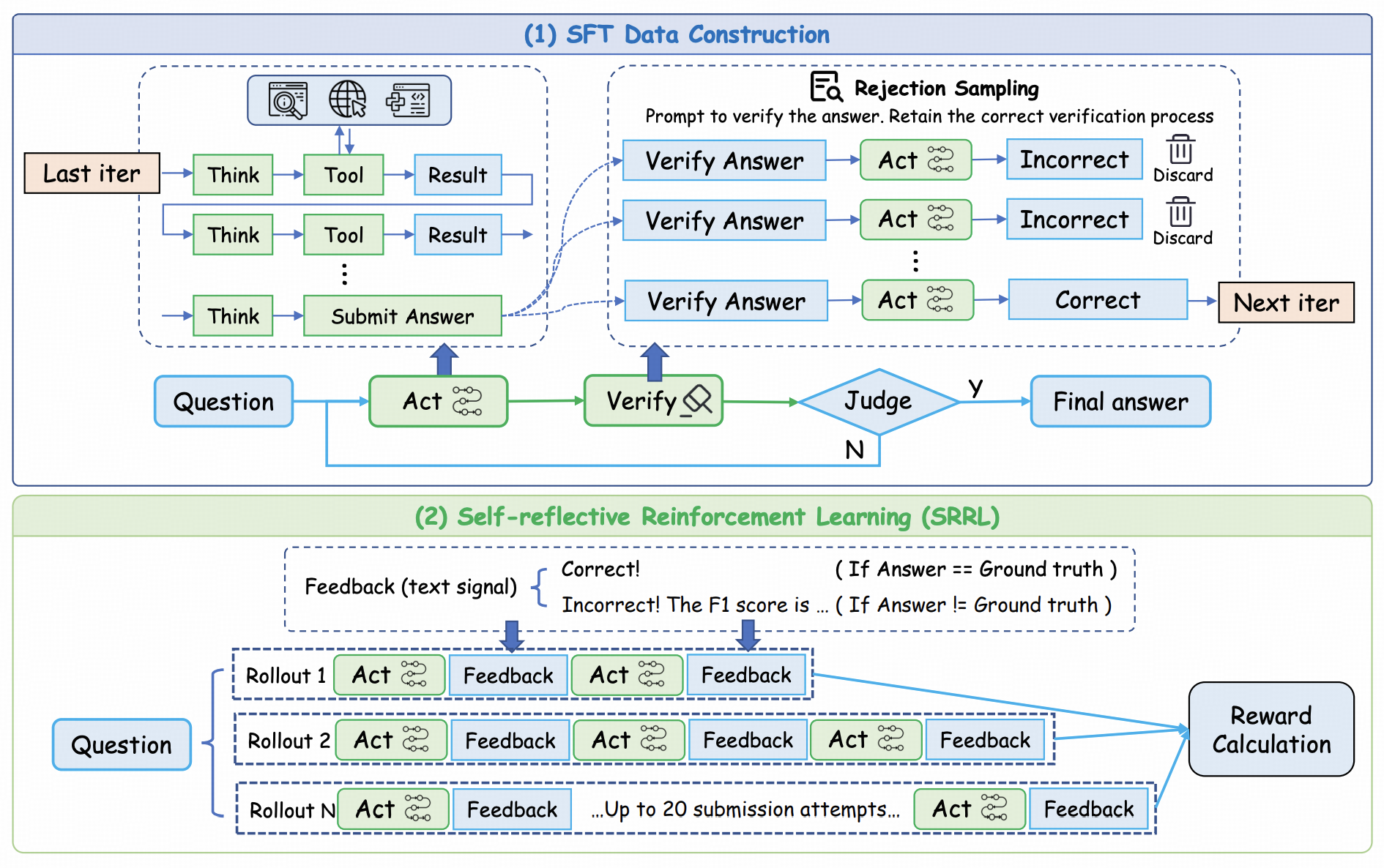
Guanzhong He, Zhen Yang, Jinxin Liu, Bin Xu, Lei Hou, Juanzi Li arXiv, 2025 paper, code WebSeer is a reinforcement learning framework for training intelligent web-based search agents capable of deeper reasoning, longer tool-use chains, and self-reflective correction. Unlike traditional Retrieval-Augmented Generation (RAG) systems, WebSeer integrates self-reflection into every stage of reasoning, enabling agents to backtrack, reformulate queries, and iteratively improve answers in real-world web environments. |
|
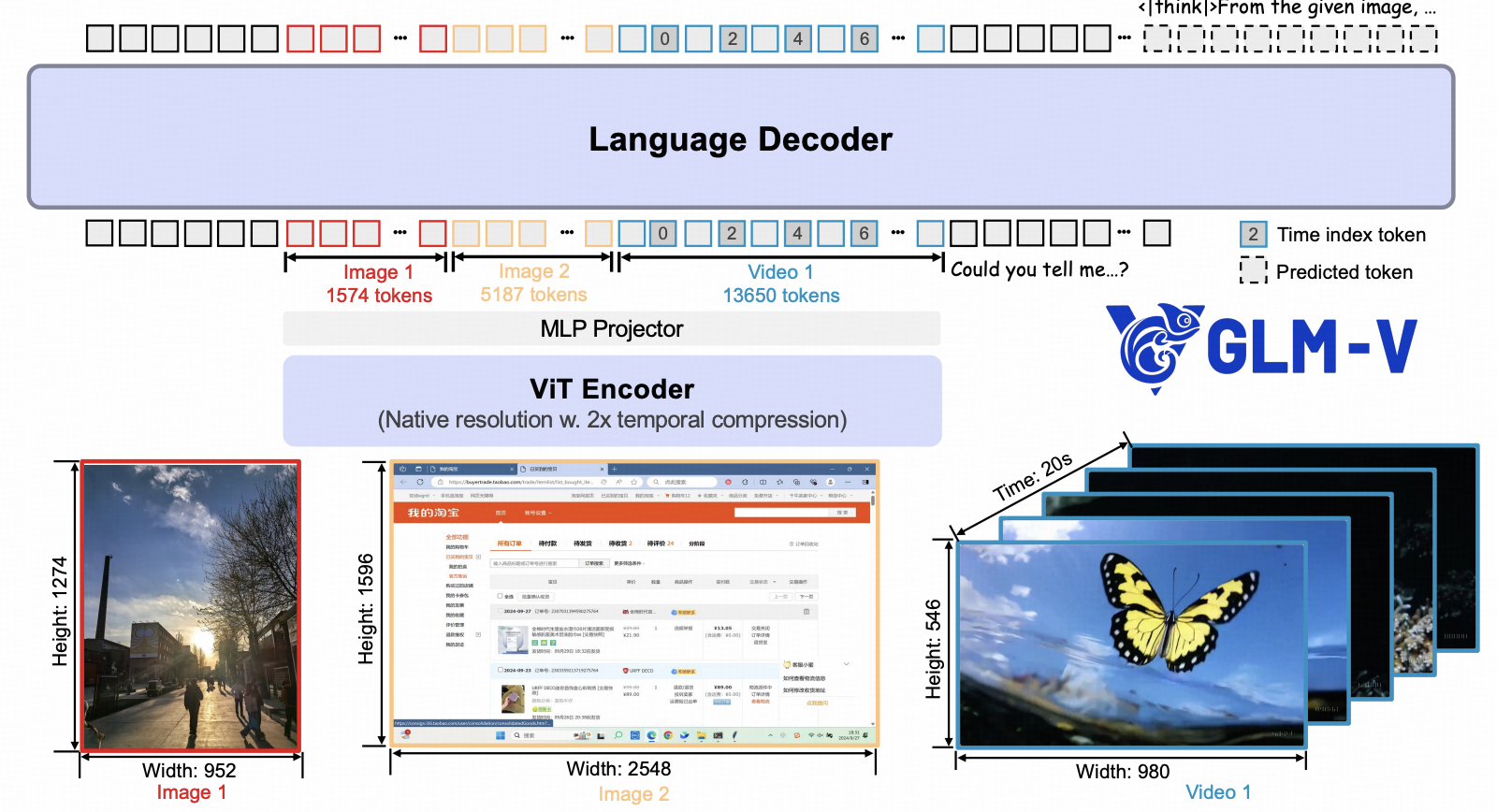
GLM-V Team, Technical Report, 2025 paper, code Vision-language models (VLMs) have become a key cornerstone of intelligent systems. As real-world AI tasks grow increasingly complex, VLMs urgently need to enhance reasoning capabilities beyond basic multimodal perception — improving accuracy, comprehensiveness, and intelligence — to enable complex problem solving, long-context understanding, and multimodal agents. Through our open-source work, we aim to explore the technological frontier together with the community while empowering more developers to create exciting and innovative applications. This open-source repository contains our GLM-4.6V, GLM-4.5V and GLM-4.1V series models. For performance and details, see Model Overview. For known issues, see Fixed and Remaining Issues. |
|
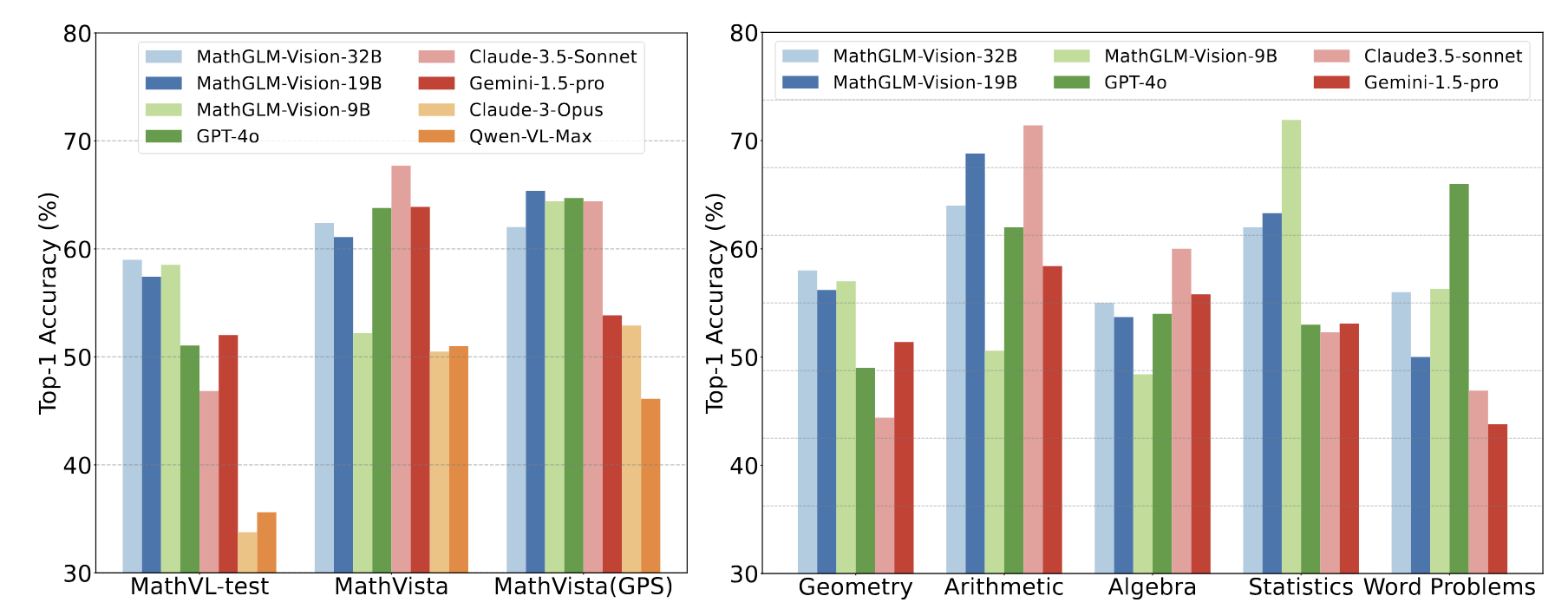
Zhen Yang*, Jinhao Chen*, Zhengxiao Du, Wenmeng Yu, Weihan Wang, Wenyi Hong, Zhihuan Jiang, Bin Xu, Yuxiao Dong, Jie Tang Manuscript, 2024 paper, code We aim to construct a fine-tuning dataset MathVL, and develop a series of specialized mathematical MLLMs MathGLM-Vision with various parameter-scale backbones. |
|
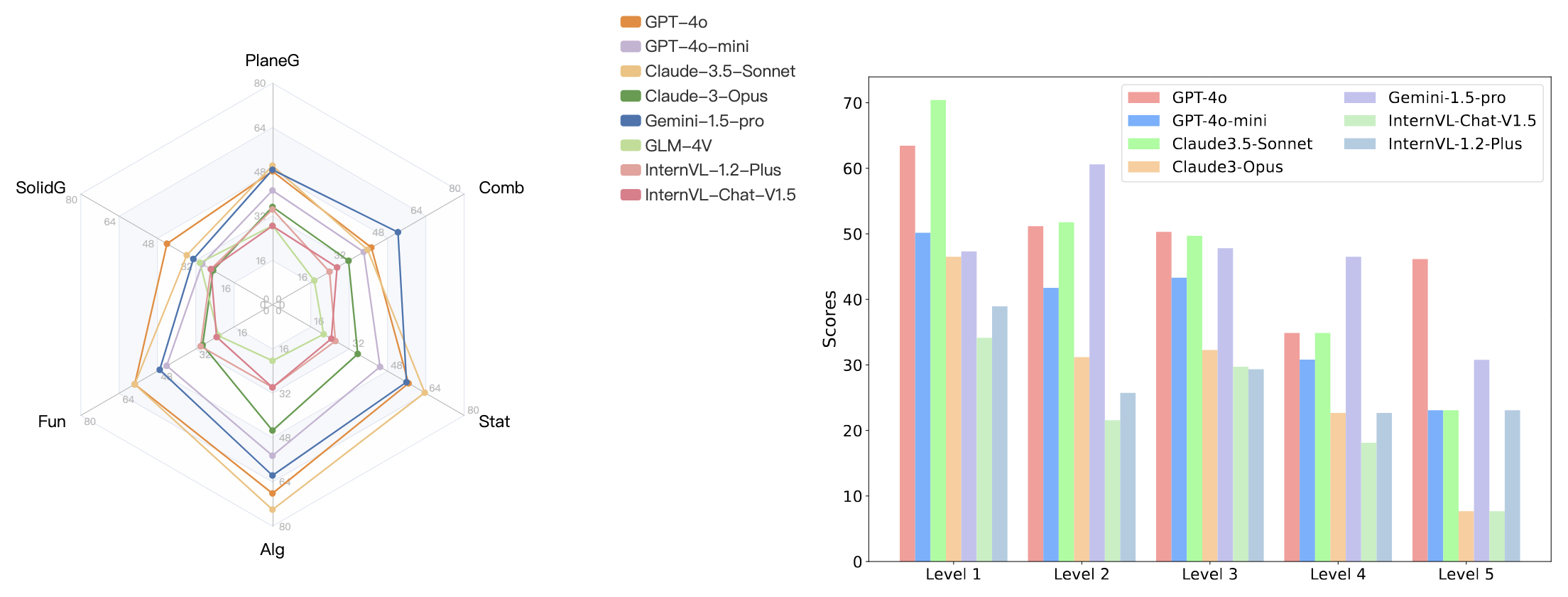
Zhihuan Jiang*, Zhen Yang*, Jinhao Chen, Zhengxiao Du, Weihan Wang, Bin Xu, Yuxiao Dong, Jie Tang Manuscript, 2024 paper, code We meticulously construct a comprehensive benchmark, named VisScience, which is utilized to assess the multi-modal scientific reasoning across the three disciplines of mathematics, physics, and chemistry. |
|
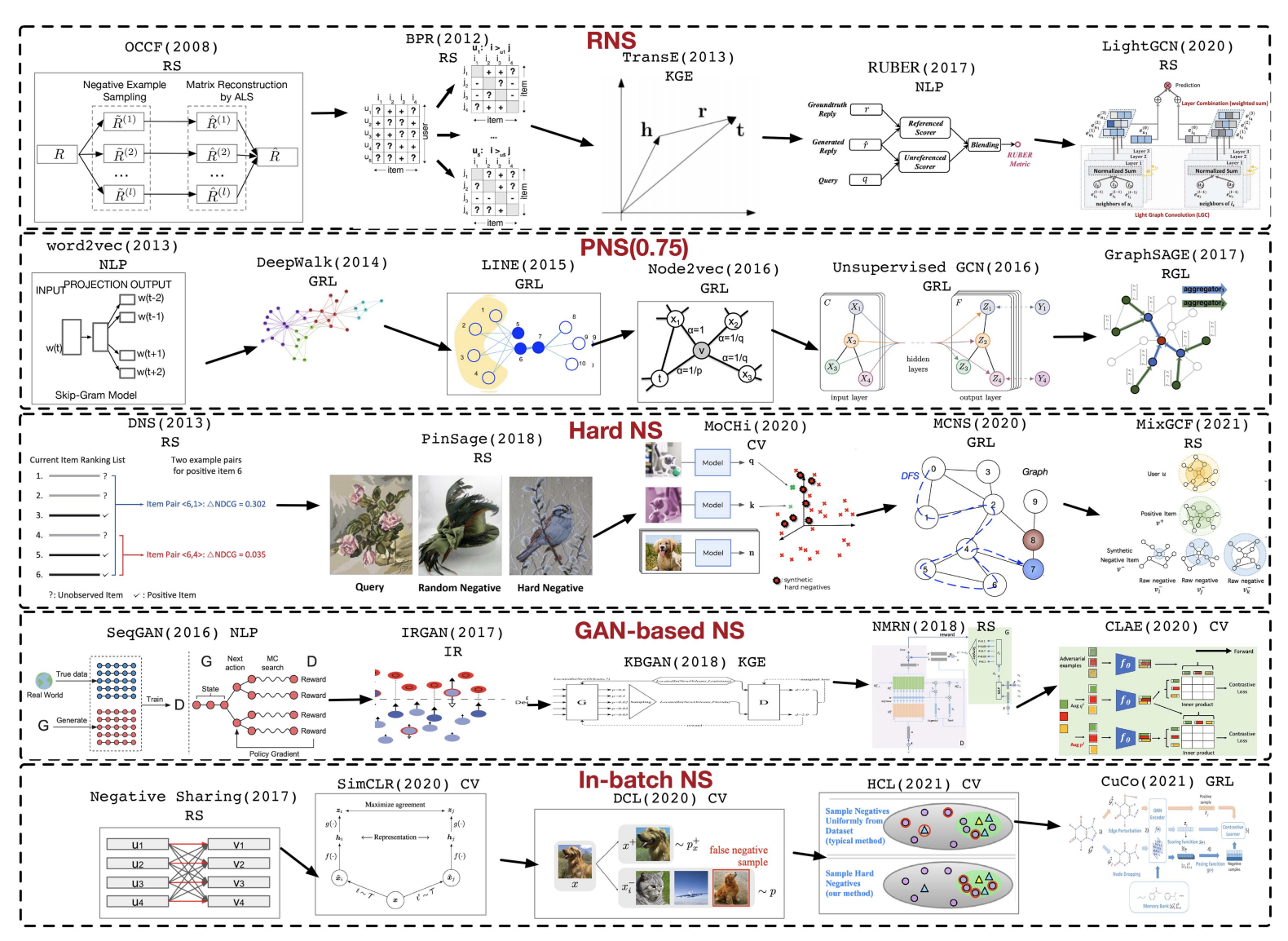
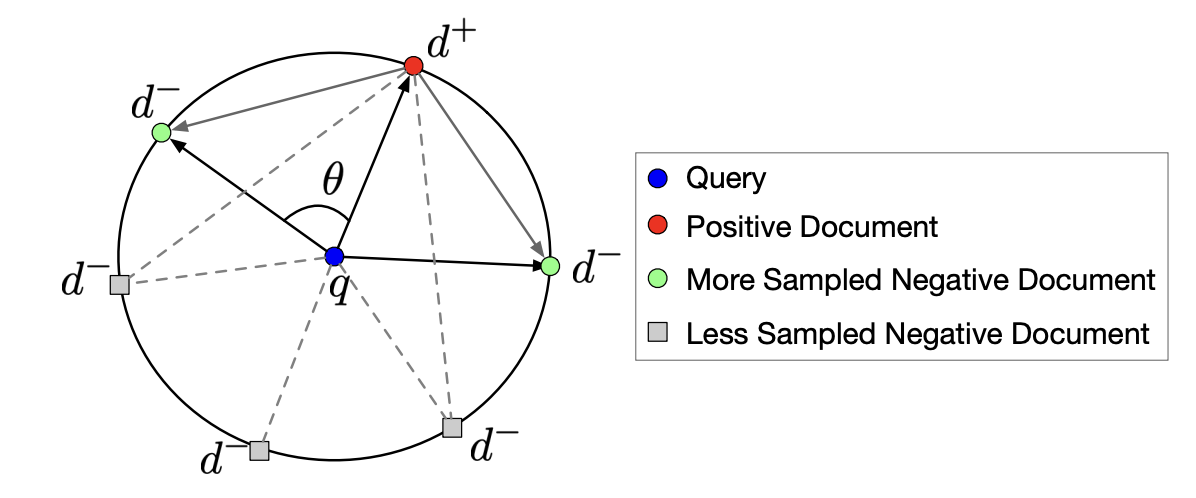
Zhen Yang, Ming Ding, Tinglin Huang, Yukuo Cen, Junshuai Song, Bin Xu, Yuxiao Dong, Jie Tang TPAMI, 2024 paper We explore the history of negative sampling, categorize the strategies used to select negative samples, and examine their practical applications. |
|
Zhen Yang, Zhou Shao, Yuxiao Dong, Jie Tang, AAAI, 2024 paper We design the quasi-triangular principle and introduce TriSampler to selectively sample more informative negatives within a prescribed constrained region. |
|
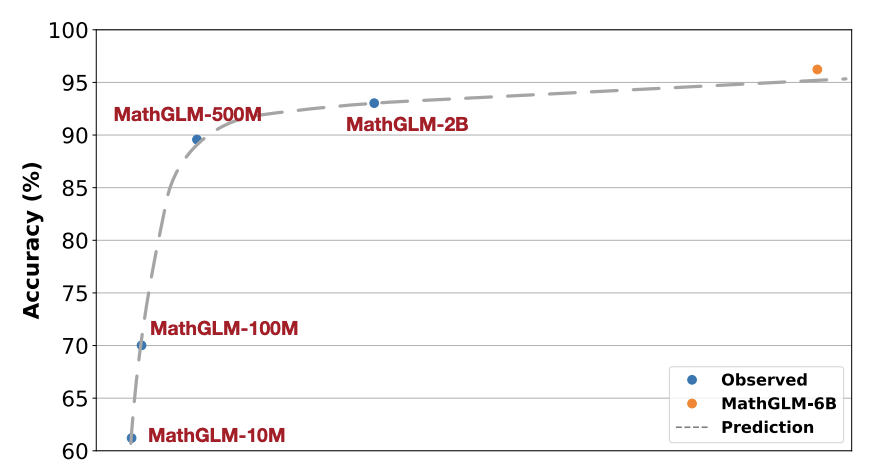
Zhen Yang*, Ming Ding*, Qingsong Lv, Zhihuan Jiang, Zehai He, Yuyi Guo, Jinfei Bai, Jie Tang, Manuscript, 2023 arxiv, code We propose a 2 billion-parameter language model MathGLM that can accurately perform multi-digit arithmetic operations with almost 100% accuracy without data leakage. |
|
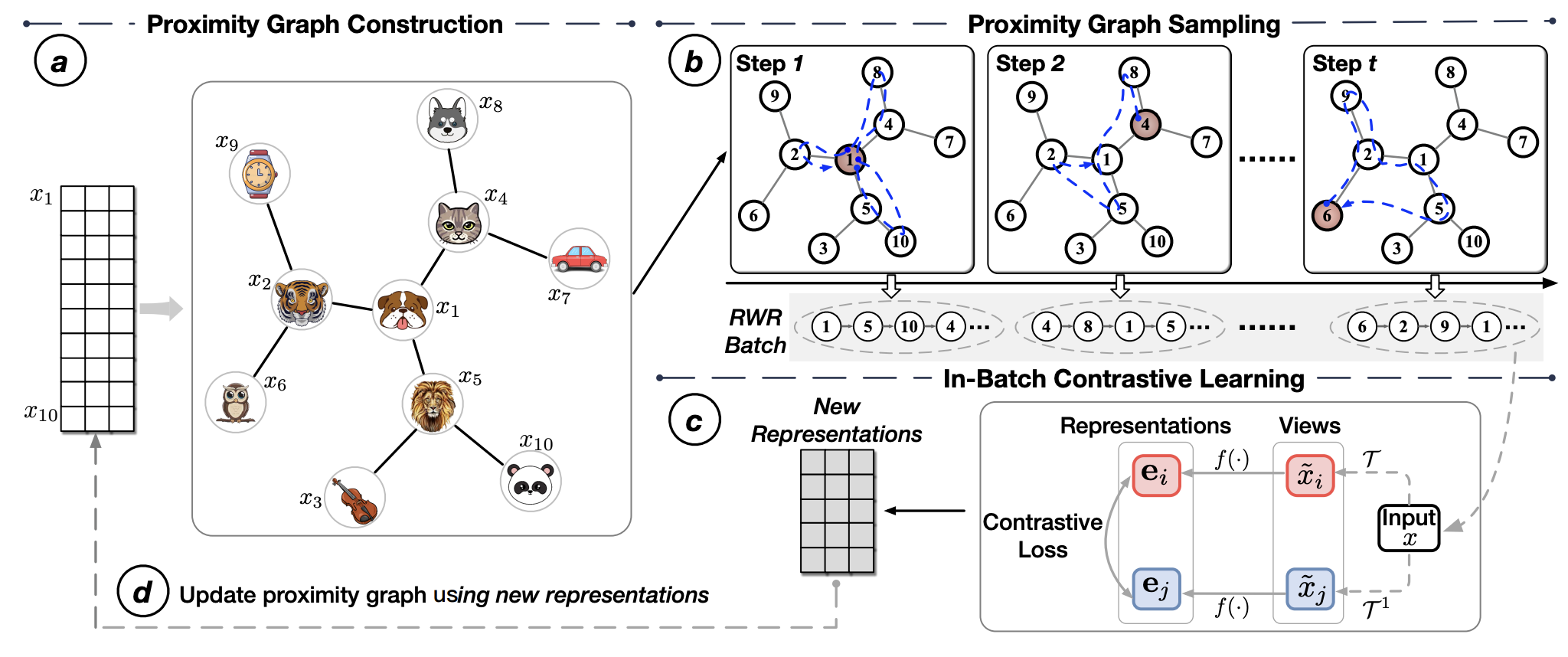
Zhen Yang*, Tinglin Huang*, Ming Ding*, Yuxiao Dong, Rex Ying, Yukuo Cen, Yangliao Geng, Jie Tang KDD, 2023 paper, code We present BatchSampler to sample mini-batches of hard-to-distinguish (i.e., hard and true negatives to each other) instances by leveraging the proximity graph and a random walk with restart. |
|
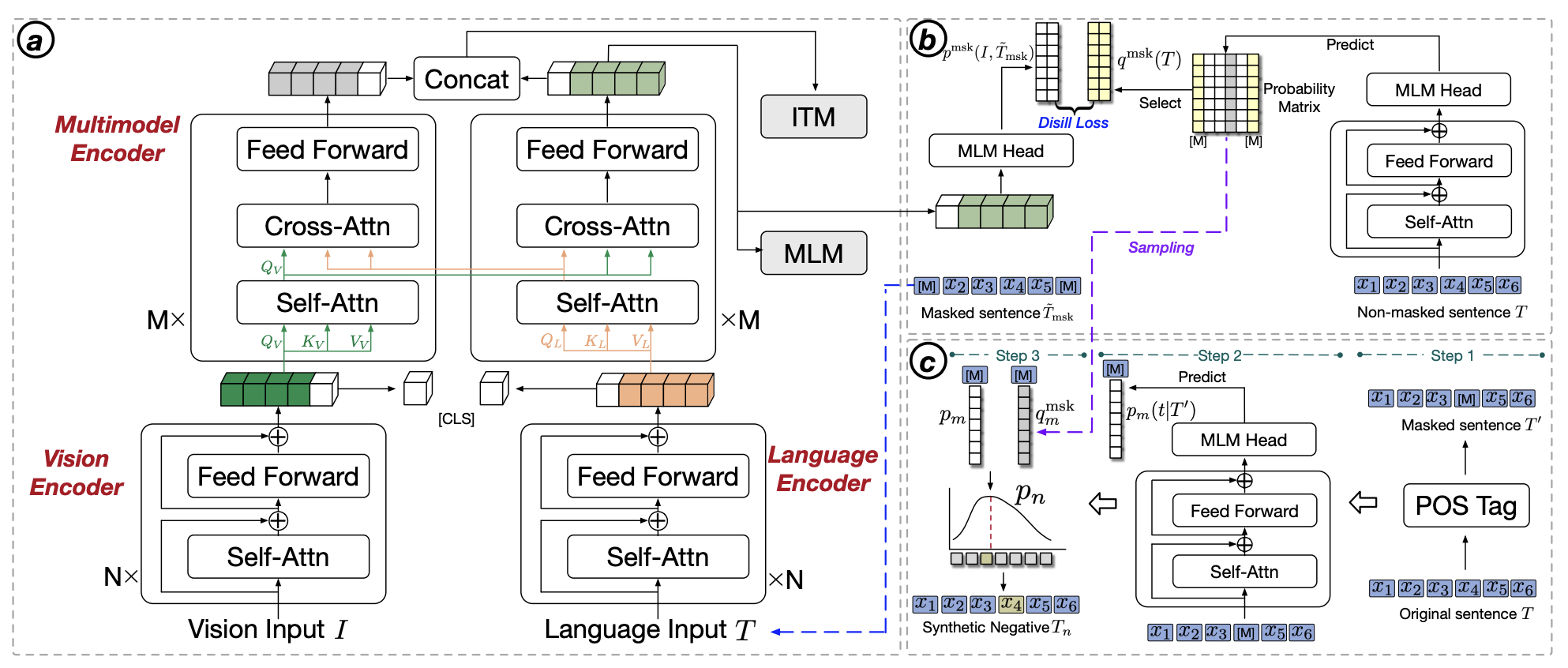
Weihan Wang*, Zhen Yang*, Bin Xu, Juanzi Li, Yankui Sun ICCV, 2023 paper We propose a novel method ViLTA that utilize a cross-distillation method to generate soft labels for enhancing the robustness of model. |
|
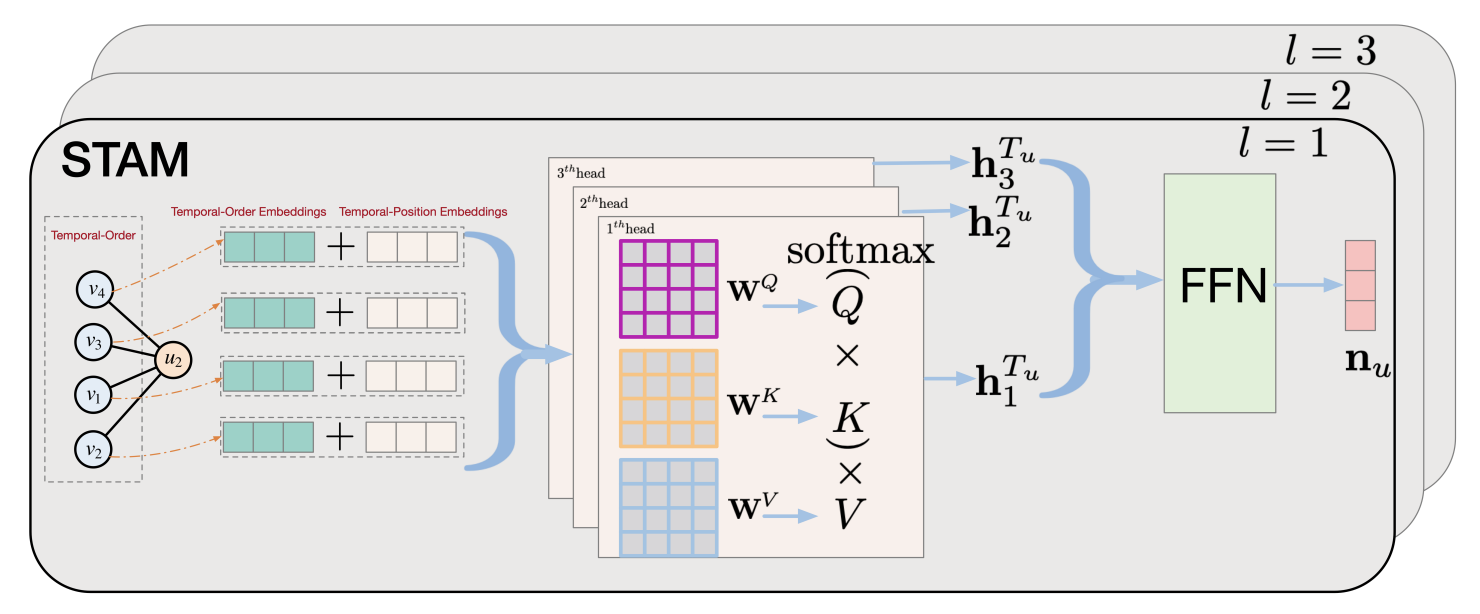
Zhen Yang, Ming Ding, Bin Xu, Hongxia Yang, Jie Tang WWW, 2022 paper, code We propose a spatiotemporal aggregation method STAM to efficiently incorporate temporal information into neighbor embedding learning. |
|
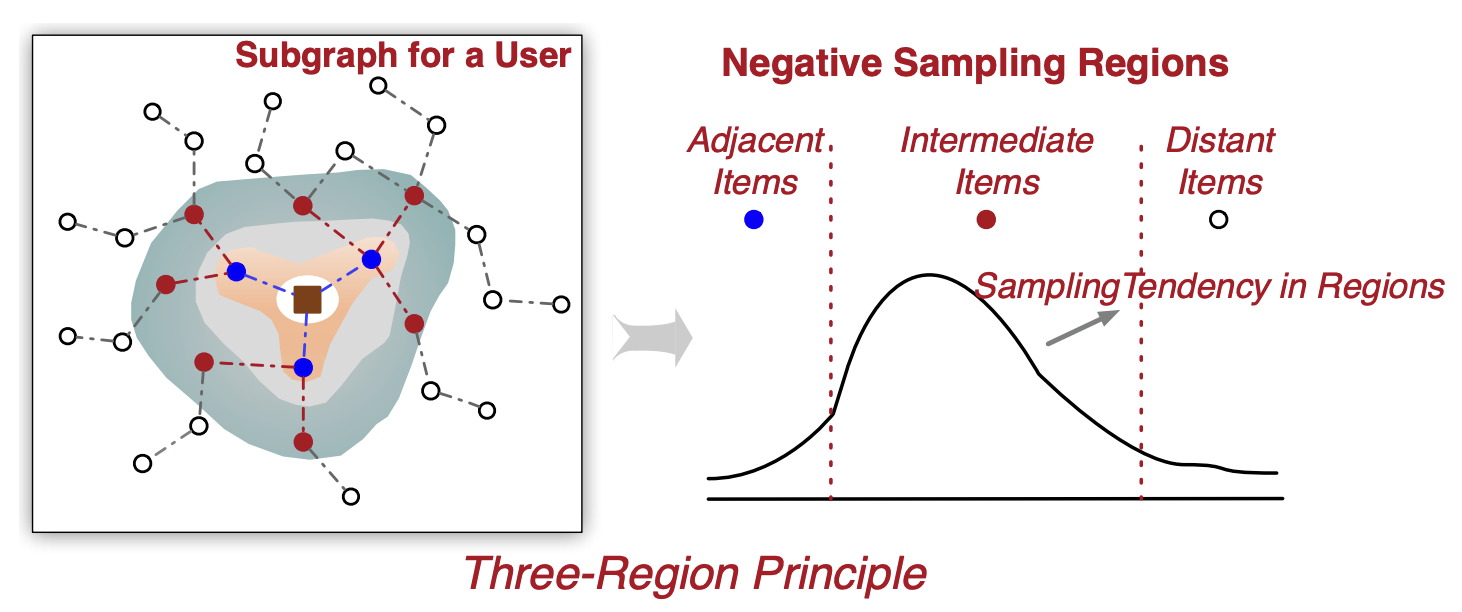
Zhen Yang, Ming Ding, Xu Zou, Jie Tang, Bin Xu, Chang Zhou, Hongxia Yang TKDE, 2022, Long oral paper, code We design three region principle to select negative candidate and propose RecNS method to sythesize hard negatives. |
|
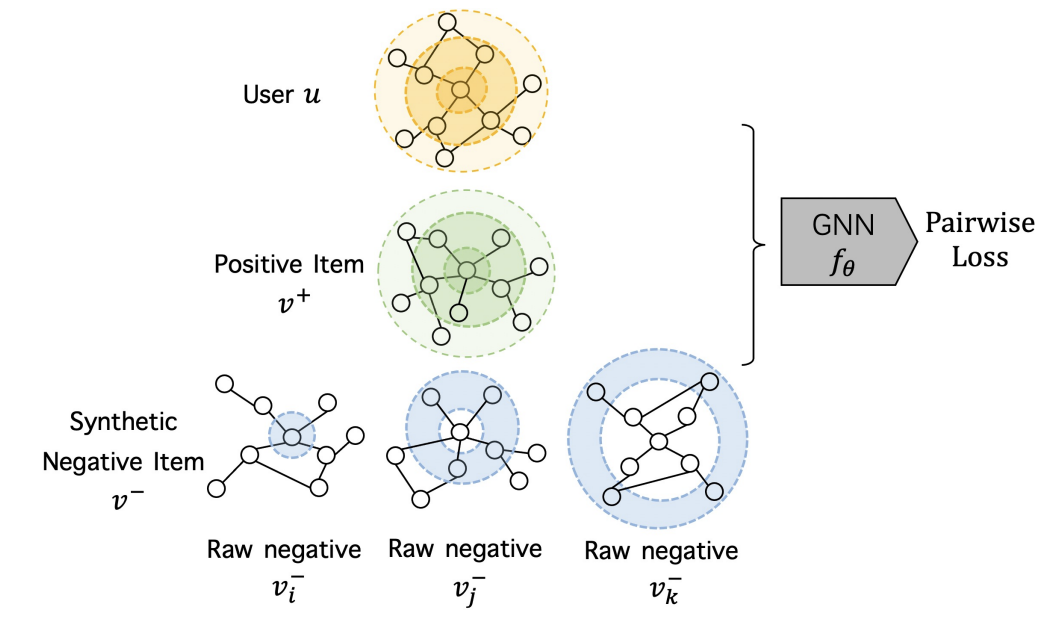
Tinglin Huang, Yuxiao Dong, Ming Ding, Zhen Yang, Wenzheng Feng, Xinyu Wang, Jie Tang KDD, 2021 paper, code We present MixGCF that can study negative sampling by leveraging both the user-item graph structure and GNNs’ aggregation process to design the hop mixing technique to synthesize hard negatives. |
|
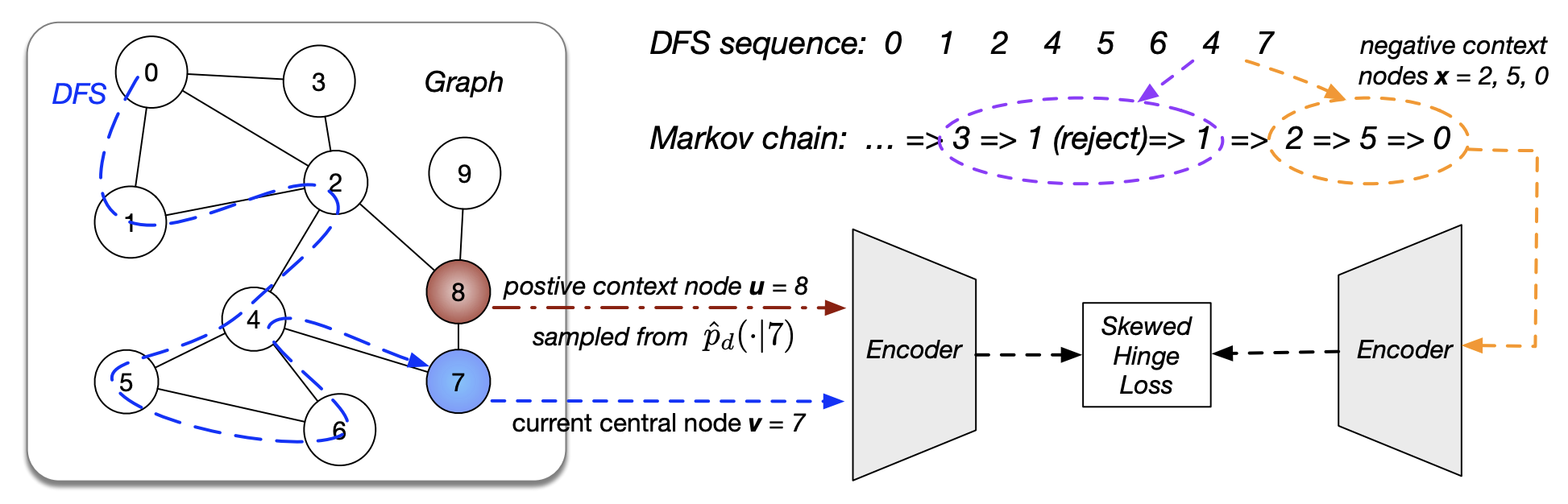
Zhen Yang*, Ming Ding*, Chang Zhou, Hongxia Yang, Jingren Zhou, Jie Tang, KDD, 2020 paper, code We develop a theory and quantify that a nice negative sampling distribution is \( p_n(u|v) \propto p_d(u|v)^\alpha \), \( 0 < \alpha < 1 \). Additionly, we propose Markov chain Monte Carlo Negative Sampling (MCNS), an effective and scalable negative sampling strategy for various tasks in graph representation learning. |
|
|
|

Thanks to Jon Barron |